
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- docker
- JPA
- java
- 도커
- 싱글톤 동시성
- 스키마 자동 생성
- Container
- 자바 동시성
- heap
- 권장 PK 전략
- PostgreSQL
- create-drop
- Database
- 로드밸런서
- ArrayList 소스코드
- thread safety
- ArrayList 길이 확장
- index
- 데이터베이스
- transaction
- load balancer
- JPA 장점
- ArrayList 가변
- 트랜잭션
- JPA란
- github
- postgres
- 멀티스레드 싱글톤
- 컨테이너
- acid
- Today
- Total
JS
Postgres는 데이터를 어디에 어떤 형태로 저장할까? 본문
Postgres는 데이터를 어디에 저장할까?
Postgres는 하드 디스크 내부에 개별 데이터베이스에 대한 모든 정보를 폴더와 수많은 파일의 형태로 저장합니다.
각각의 다른 파일들은 해당 데이터베이스의 여러가지 정보를 담고 있습니다.
ex) 테이블 정보, 인덱스, 고유 키
그렇다면 실제로 이런 폴더와 파일들이 어디에 어떤 형태로 존재하는지 알아보겠습니다.
우선 Postgres가 어떤 디렉토리에 데이터를 저장하고 있는지 아래 명령어를 통해 확인해본 후 자세히 살펴보겠습니다.
SHOW data_directory;
위 명령어를 통해 어떤 디렉토리에 데이터가 저장되고 있는지 확인했으니 해당 디렉토리로 이동해보겠습니다.

위에 보이는 여러개의 폴더들 중 우리가 원하는 데이터가 존재하는 base 폴더로 이동해보겠습니다.
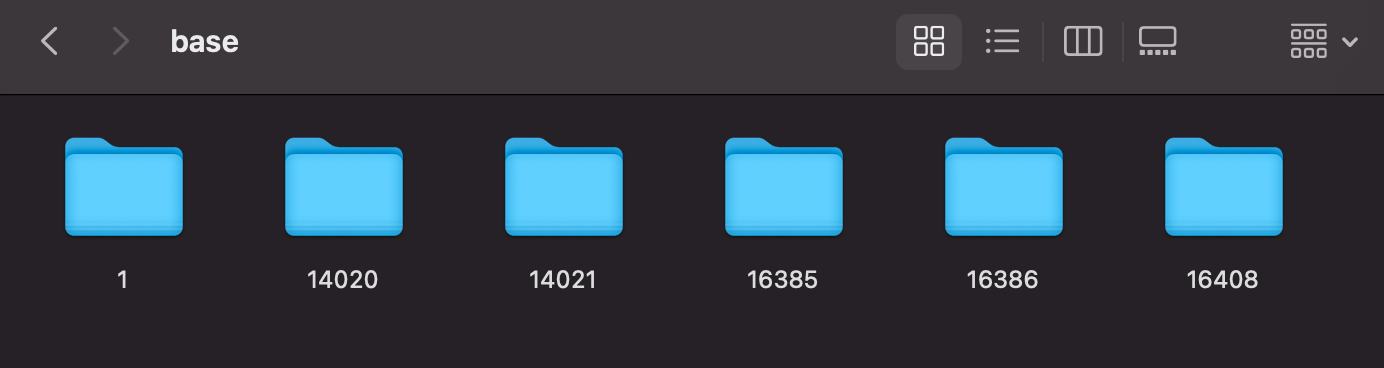
로컬 환경에 존재하는 데이터베이스 별 데이터가 폴더의 형태로 존재합니다.
하지만 이렇게만 봐서는 어떤 폴더가 어떤 데이터베이스의 데이터를 담고 있는지 구분하기가 어렵습니다.
아래 명령어를 통해 각 폴더가 어떤 데이터베이스의 데이터를 담고 있는지 확인을 해보겠습니다.
SELECT oid, datname
FROM pg_database;
위의 base 폴더에 존재했던 숫자로 네이밍 되어있는 폴더들이 각각 어떤 데이터베이스의 폴더인지를 확인할 수 있습니다.
현재 데모용으로 작업중인 데이터베이스는 instagram 이므로 16408 폴더로 이동해보겠습니다.

해당 폴더에는 파일명만 봐서는 아무 정보도 알 수 없는 파일들이 수많이 존재합니다.
이 모든 파일들은 데이터베이스 내부의 raw data입니다.
그럼 각 파일들은 어떤 데이터를 담고 있을까요?
대충 봤을때 파일 하나하나가 개별 테이블을 나타내기에는 파일 수가 너무 많고, 개별 row를 나타내기에는 파일 수가 너무 적은 것처럼 보입니다.
다른 명령어를 통해 각 파일이 어떤 데이터를 담고 있는지 확인해보겠습니다.
SELECT * FROM pg_class;
많은 데이터가 반환되는 것을 볼 수 있습니다.
몇몇 row들은 테이블 하나에 대한 데이터를 담고 있는 것 처럼 보이지만 모든 row가 그렇지는 않아 보이죠?pkey, id_seq, index 등 여러가지가 존재하는 것을 확인할 수 있습니다.
여기서의 각 row는 조금 전 위에서 봤던 파일 하나하나에 담긴 데이터 객체에 담긴 데이터를 보여주고 있습니다.
데이터 객체는 테이블뿐만 아니라 index, sequence, primary key 등에 대한 정보를 담고 있습니다.
그렇다면 users 테이블에 대한 정보가 어디에 담겨 있는지 확인해보겠습니다.
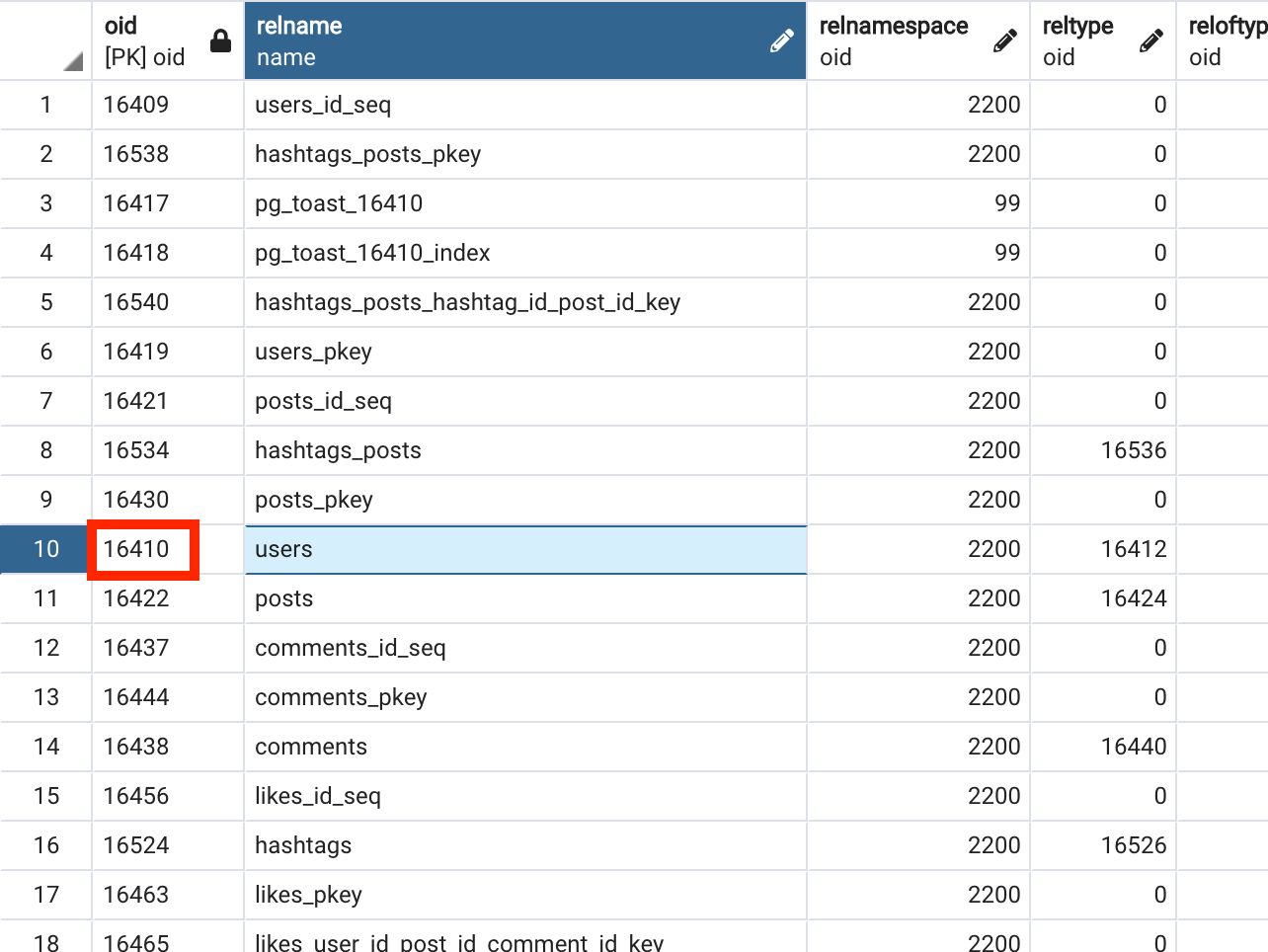
relname 컬럼에 값이 users인 row를 찾아가면 16410 이라는 값의 oid를 가지고 있는 것을 확인할 수 있습니다.
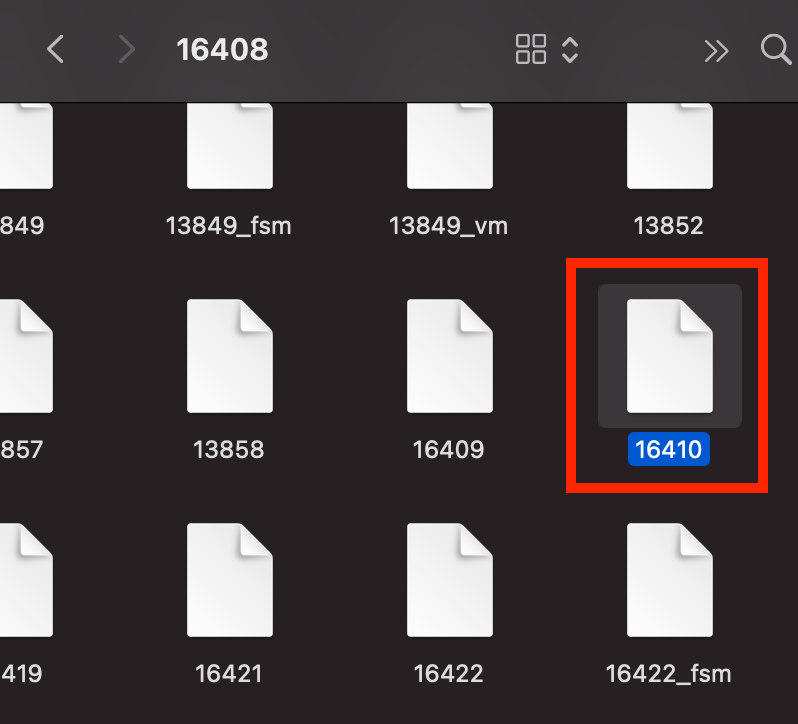
다시 한번 16480 폴더를 찾아가서 16410 이라는 파일을 찾았습니다.
해당 파일은 users 테이블에 대한 모든 정보를 담고 있는 파일이라는 뜻이죠.
이렇게 Postgres는 내부적으로 모든 데이터를 폴더와 파일의 형태로 로컬 저장공간에 저장해두고 관리합니다.
그렇다면 눈으로 확인할 수 없어 보이는 이 파일들은 어떤 구조를 띄고 있을까요?
Postgres는 데이터를 어떤 형태로 저장할까?
위에서는 Postgres가 로컬 환경의 어떤 디렉토리에 데이터를 저장하고 관리하는지 알아봤습니다.
그렇다면 실제로 해당 파일들은 어떤 형태로 저장이 되어있는지 알아보겠습니다.
시작하기전에 먼저 알아야할 단어/개념들이 있습니다.
- Heap(Heap File): 특정 테이블에 존재하는 모든 데이터(rows)를 담고 있는 공간(파일) 입니다.
- Tuple(Item): 특정 테이블의 row 하나에 대한 데이터를 담고 있는 곳입니다.
- Block(Page): Heap File은 여러개의 Block(Page)로 나뉘어져 구성됩니다. 각 Block(Page) 는 여러개의 rows 데이터를 담고 있습니다.
위에서 봤던 users 테이블에 대한 데이터를 담고 있는 16410 파일은 테이블에 대한 모든 데이터를 담고 있는 Heap File 입니다.
참고) 여기서의 Heap(Heap File)은 자료구조 Heap과는 아무런 관계가 없습니다.
Heap File
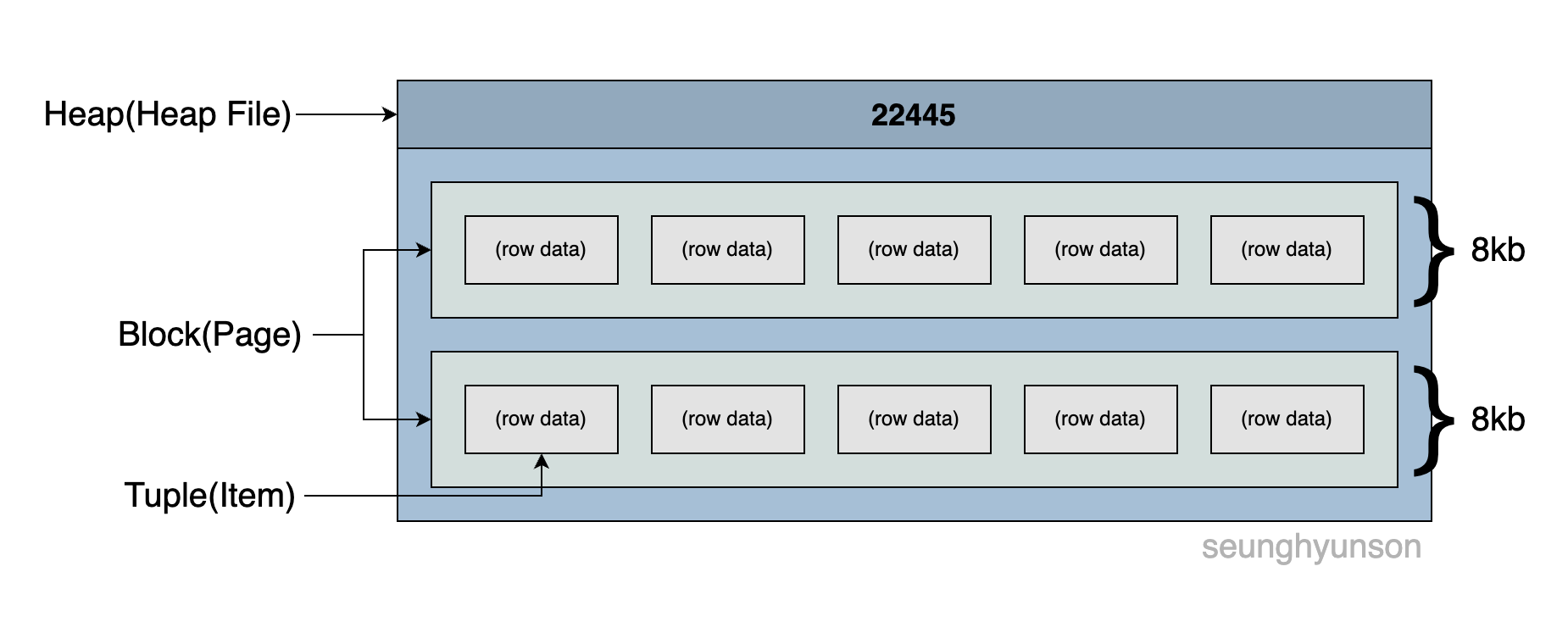
위 다이어그램과 같이, 하나의 Heap File 은 여러개의 Block(Page) 로 나뉘어져 있고, 각 Block(Page) 는 여러개의 Tuple(Item) 을 담고 있습니다.
하나의 Block은 안에 몇개의 Tuple이 존재하던 상관없이 8kb의 사이즈를 가지고 있습니다.
내부적으로 데이터가 어떤 형태로 저장되는지는 재미도 없고 크게 중요하게 느껴지지 않을 수 있지만, 실제 쿼리 호출 시 Full Table Scan을 하거나 Index를 활용할 때 내부적으로 어떻게 동작하는지를 이해하고 어떤 방식이 더 효율적인지를 비교하여 튜닝을 할 때 도움이 될 수 있습니다.
다음에는 이번 포스팅에서 정리한 내용을 바탕으로 Index에 대해 다뤄볼 예정입니다.
'Database' 카테고리의 다른 글
| 쿼리 성능 분석하기 (PostgreSQL) (5) | 2022.02.24 |
|---|---|
| Database Index란? (0) | 2022.02.14 |
| INTERVAL을 이용한 시간 계산하기 (0) | 2022.02.01 |
| [ACID #3] Isolation이란? 트랜잭션의 격리 수준(isolation level)이란? (0) | 2022.01.18 |
| [ACID #2] Atomicity란? 아토믹한 트랜잭션이란? (0) | 2022.01.11 |



